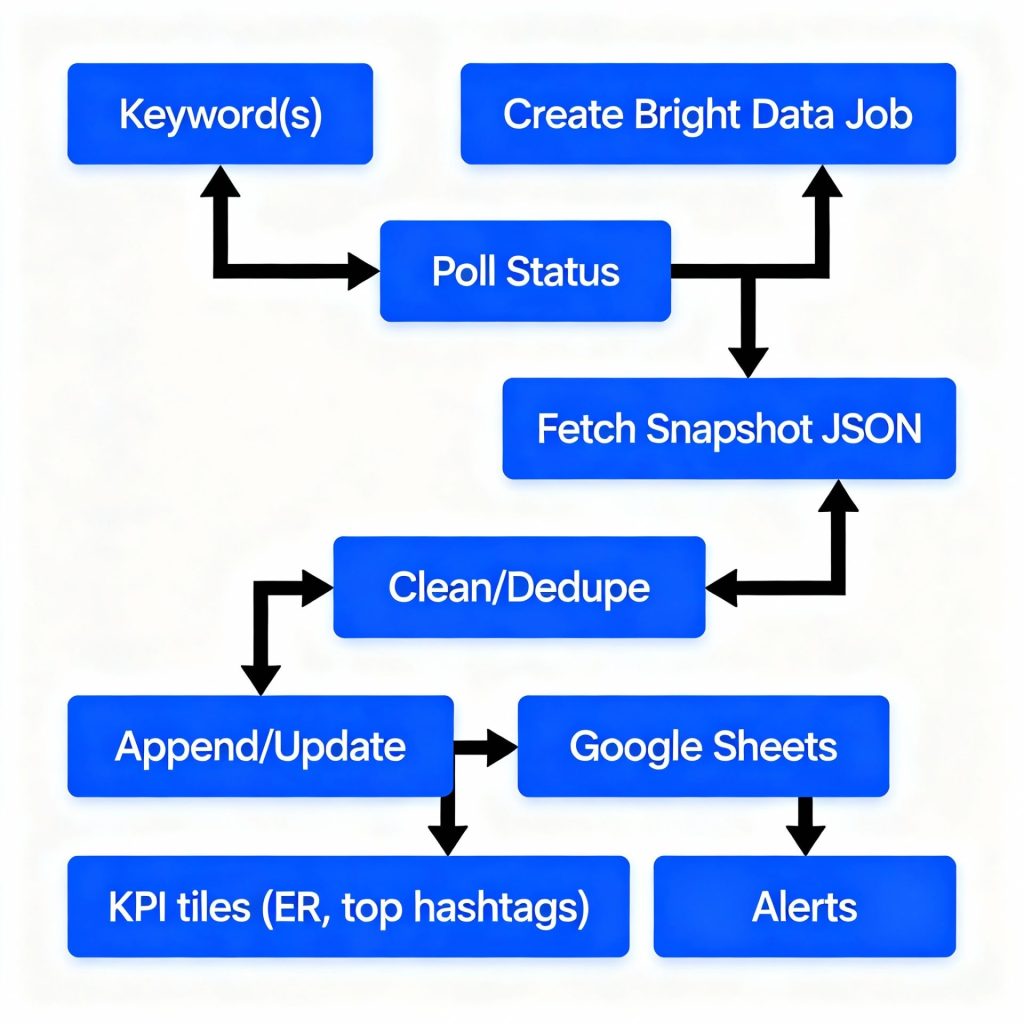
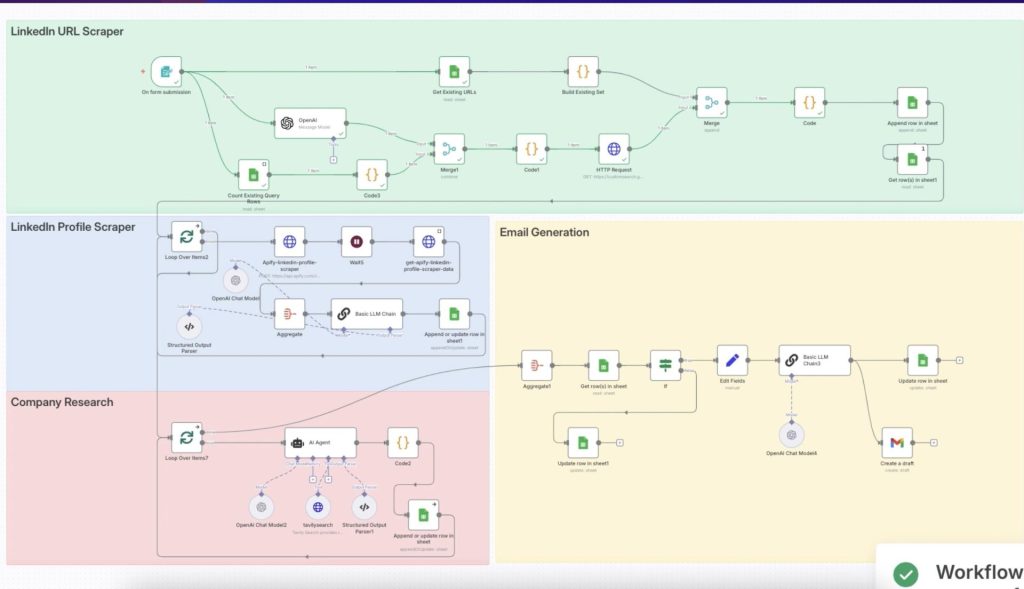
LinkedIn Lead Machine là một quy trình tự động hóa toàn diện, giúp đơn giản hóa việc tìm kiếm khách hàng tiềm năng và tiếp cận trên LinkedIn bằng cách kết hợp nghiên cứu thông minh từ AI với các bước tự động mượt mà. Hệ thống sẽ tìm ra hồ sơ LinkedIn phù hợp, thu thập thông tin nghề nghiệp, phân tích dữ liệu doanh nghiệp và tạo ra email tiếp cận được cá nhân hóa — tất cả mà không cần thao tác thủ công.
Bằng cách tích hợp các công cụ như n8n, OpenAI, Apify, Tavily và Google Sheets, hệ thống xử lý toàn bộ quy trình — từ tìm kiếm và làm giàu dữ liệu khách hàng tiềm năng, soạn email, cho đến lưu trữ — chỉ trong một luồng làm việc trơn tru.
Được thiết kế cho founder, đội ngũ sales và marketer B2B, workflow này giúp loại bỏ các tác vụ lặp đi lặp lại, tiết kiệm 15–20 giờ mỗi tuần, và mở rộng quy mô tiếp cận khách hàng một cách dễ dàng. Với khả năng xử lý lỗi mạnh mẽ, tích hợp API đa dạng và cá nhân hóa dựa trên AI, LinkedIn Lead Machine giúp bạn tập trung ít hơn vào công việc quản trị và nhiều hơn vào việc chốt deal.
Thông tin
Vấn Đề Thực Sự Mà Tự Động Hóa Này Giải Quyết
Việc tìm kiếm khách hàng tiềm năng (sales prospecting) về cơ bản không thay đổi trong hàng chục năm, dù các công cụ có tiến hóa. Bạn vẫn phải làm 4 việc quen thuộc: tìm khách hàng tiềm năng, nghiên cứu họ, nghiên cứu công ty của họ và viết thông điệp tiếp cận cá nhân hóa. Khác biệt duy nhất là: việc từng cần một trợ lý nghiên cứu riêng, giờ lại đổ dồn lên vai từng nhân viên sales – những người vốn đã phải chạy KPI, chăm sóc khách hàng hiện có và chốt deal.
Điều này tạo ra một bài toán phân bổ thời gian “khắc nghiệt”. Nghiên cứu cho thấy nhân viên sales B2B dành tới 65–70% thời gian cho các hoạt động không trực tiếp bán hàng, trong đó nghiên cứu khách hàng tiềm năng là khoản tốn thời gian nhất. Một nhân viên sales điển hình có thể mất 15–20 giờ mỗi tuần chỉ để gom thông tin cơ bản trước khi có thể bắt đầu trò chuyện thực sự.
LinkedIn Lead Machine không chỉ rút ngắn quy trình này mà còn tái cấu trúc nó. Thay vì làm tuần tự (nghiên cứu xong từng khách hàng rồi mới qua người tiếp theo), bạn chỉ nhập tiêu chí một lần và hệ thống trả về kết quả hàng loạt — vốn phải mất cả ngày mới làm thủ công được.
Điểm Khác Biệt Của Cách Tiếp Cận Này
Trí Tuệ Ở Quy Mô Lớn
Công cụ tự động truyền thống coi prospecting như nhập liệu: copy từ A sang B mà không hiểu ngữ cảnh. Automation này ứng dụng AI ở nhiều giai đoạn để thực sự hiểu dữ liệu và tại sao nó quan trọng.
Ví dụ: khi gặp hồ sơ “Director of Operations tại một công ty sản xuất”, hệ thống không chỉ copy chức danh, mà còn phân tích xem họ quan tâm đến vấn đề gì, những thách thức vận hành nào có thể được giải quyết bằng AI, và xây dựng thông điệp xoay quanh hiệu suất và tối ưu quy trình.
Nghiên Cứu Doanh Nghiệp Theo Ngữ Cảnh
Đa số công cụ chỉ dừng lại ở thông tin liên hệ. Automation này đi sâu hơn bằng cách nghiên cứu công ty của từng khách hàng theo thời gian thực: gọi vốn, ra mắt sản phẩm, kế hoạch mở rộng, vấn đề về trải nghiệm khách hàng… Những thông tin thời sự này biến một email “lạnh” thành một cuộc trò chuyện kinh doanh có liên quan.
Tích Hợp Dữ Liệu Đa Kênh
Hệ thống kết hợp dữ liệu LinkedIn, thông tin công ty và nghiên cứu thị trường để tạo cái nhìn 3 chiều về mỗi khách hàng. Bạn không chỉ tiếp cận “John Smith, VP Marketing” mà là “John Smith, VP Marketing tại TechCorp, công ty vừa gọi vốn Series B và đang mở rộng sang phân tích khách hàng bằng AI”.
Tạo Thông Điệp Linh Hoạt
AI không dùng template cứng nhắc mà tạo thông điệp độc nhất, tìm điểm kết nối mạnh nhất giữa sản phẩm/dịch vụ của bạn và tình huống cụ thể của khách hàng. Có lúc dựa vào việc họ vừa được thăng chức, có lúc dựa vào sản phẩm mới công ty họ ra mắt, hoặc một mối quan tâm chung.
Automation Này Thực Sự Mang Lại Gì Cho Doanh Nghiệp
Tái Phân Bổ Thời Gian
Thay vì 15 giờ nghiên cứu 50 khách hàng, giờ bạn chỉ mất 2 giờ thiết lập chiến dịch và duyệt kết quả. 13 giờ còn lại được trả về cho công việc bán hàng thực sự: gọi follow-up, viết proposal, gặp khách, xây dựng quan hệ.
Nâng Cao Chất Lượng
Khi áp lực KPI lớn, nghiên cứu thủ công dễ trở nên cẩu thả: bỏ qua nghiên cứu công ty, dùng email mẫu chung, gửi outreach kém chất lượng. Automation giữ chất lượng nhất quán vì AI không mệt mỏi và không cắt xén quy trình.
Pipeline Ổn Định
Prospecting thủ công phụ thuộc vào thời gian bạn bỏ ra hàng tuần. Với automation, bạn có dòng khách hàng tiềm năng đều đặn, bất kể bạn bận rộn chốt deal thế nào.
Lợi Thế Cạnh Tranh
Trong khi đối thủ còn copy profile LinkedIn vào Excel, bạn đã trò chuyện với khách hàng bằng thông điệp sâu sắc, có nghiên cứu, tạo sự khác biệt ngay từ đầu.
Đối Tượng Phù Hợp (và Không Phù Hợp)
Phù Hợp
-
Dịch vụ B2B: Tư vấn, agency, dịch vụ chuyên nghiệp, nơi deal size đủ lớn (≥ 5.000 USD) để xứng đáng cá nhân hóa.
-
Sales SaaS: Đặc biệt khi bán cho những vai trò/ngành cụ thể, cần nhắm chính xác hơn là số lượng.
-
Business Development: Người phải xác định & đánh giá khách hàng tiềm năng trong phân khúc rõ ràng.
-
Sales Ops: Người chịu trách nhiệm mở rộng prospecting mà không tăng headcount.
Không Phù Hợp
-
Bán số lượng lớn, ít tương tác: Gửi 1.000+ email chung mỗi ngày thì mức độ cá nhân hóa này quá thừa.
-
B2C: Hệ thống này thiết kế cho outreach B2B, không dành cho marketing tiêu dùng.
-
Dự án đơn lẻ: Thiết lập tốn công, chỉ hợp lý nếu dùng thường xuyên.
-
Ngành siết chặt compliance: Nếu ngành bạn có quy định nghiêm về automation/data, cần tham vấn pháp lý trước.
Kỳ Vọng và Kết Quả Thực Tế
Thành Công Sẽ Trông Như Thế Nào?
Một chiến dịch 50 khách hàng sau khi triển khai:
-
40–45 hồ sơ xử lý thành công (tỷ lệ 85–90%)
-
25–30 khách có email hợp lệ (60–70% coverage)
-
Thông điệp tiếp cận được cá nhân hóa, gắn với chi tiết cá nhân/công ty
-
Tỷ lệ phản hồi 5–10% (so với trung bình thị trường 1–2%)
-
Tiết kiệm 15–20 giờ mỗi chiến dịch so với thủ công
Lộ Trình Triển Khai
-
Tuần 1: Thiết lập tài khoản, cấu hình API, test (6–8h)
-
Tuần 2: Chạy chiến dịch thật, tinh chỉnh (4–5h)
-
Tuần 3+: Quản lý thường xuyên (30 phút/chiến dịch)
Chuẩn Đánh Giá Chất Lượng
-
90%+ thông điệp có chi tiết nghề nghiệp của khách
-
70%+ nhắc đến thông tin công ty hoặc tin tức mới
-
50%+ chỉ ra được điểm kết nối với giải pháp của bạn
-
0% lỗi ngớ ngẩn hoặc thông tin vô nghĩa
Hạn Chế Cần Hiểu
-
Phụ thuộc dữ liệu: Chỉ tốt bằng dữ liệu LinkedIn/web công khai. Profile riêng tư hay công ty ít thông tin sẽ hạn chế insight.
-
Giới hạn ngữ cảnh: AI hiểu ngữ cảnh nghề nghiệp tốt, nhưng không thay được “trực giác” của sales kỳ cựu.
-
Thực tế phản hồi: Cá nhân hóa giúp tăng tỷ lệ phản hồi, nhưng automation không thay thế được giá trị sản phẩm/thị trường/outreach strategy.
-
Cần bảo trì: API đổi, dịch vụ cập nhật → phải theo dõi và điều chỉnh. Đây không phải “cài một lần rồi quên”.
Chiến Lược Tích Hợp Vào Doanh Nghiệp
Tích Hợp Workflow
Automation phù hợp nhất ở top-of-funnel: không thay thế việc xây quan hệ, mà nâng chất lượng & số lượng khách hàng đầu pipeline.
-
Trước automation: xác định & nghiên cứu khách hàng
-
Sau automation: quản lý cuộc trò chuyện & xây quan hệ
Mở Rộng Đội Nhóm
Automation giúp một người làm việc như nhiều researcher. Đặc biệt hữu ích cho:
-
Team nhỏ không có researcher riêng
-
Team tăng trưởng nhanh nhưng chưa kịp tuyển dụng
-
Thị trường ngách cần chuyên môn sâu để xác định prospect
Khung ROI
Tính lợi nhuận dựa trên:
-
Thời gian tiết kiệm: (Giờ/chiến dịch) × (Chi phí giờ) × (Số chiến dịch/tháng)
-
Nâng chất lượng: (Tăng response rate) × (Giá trị deal trung bình) × (Tỷ lệ chốt)
-
Ổn định pipeline: (Giá trị pipeline predictable) × (Giảm chi phí tuyển dụng)
Thông thường, ROI đạt 300–800% trong 6 tháng đầu, nếu hiện tại bạn đang prospect thủ công và automation này giúp tiết kiệm thời gian hoặc tăng tỷ lệ phản hồi rõ rệt.
Insight quan trọng: Automation này không chỉ tăng tốc quá trình cũ mà còn tái định nghĩa prospecting, nơi trí tuệ & cá nhân hóa cùng mở rộng theo quy mô, thay vì phải đánh đổi giữa hai yếu tố.
Cỗ Máy Tìm Khách LinkedIn – Hướng Dẫn Triển Khai Hoàn Chỉnh
Tự động này làm gì
Quy trình này biến việc tìm kiếm khách hàng tiềm năng trên LinkedIn từ hàng giờ thủ công thành một hệ thống tự động: tìm, nghiên cứu và tạo thông điệp tiếp cận cá nhân hóa. Bạn chỉ cần nhập tiêu chí tìm kiếm qua một form đơn giản, hệ thống sẽ tự động tìm hồ sơ LinkedIn, thu thập thông tin nghề nghiệp, nghiên cứu công ty, và tạo sẵn email nháp để gửi đi.
Thời gian triển khai: 2-3 giờ
Trình độ yêu cầu: Người mới (có hướng dẫn chi tiết)
Bạn tiết kiệm được: 15-20 giờ/tuần công việc thủ công
Trước khi bắt đầu
Tài khoản & công cụ cần có
- Tài khoản n8n (nền tảng tự động hóa quy trình)
- Google Cloud Platform (để tạo Custom Search Engine)
- Tài khoản OpenAI (xử lý AI)
- Tài khoản Apify (dùng để scrape LinkedIn)
- Tài khoản Tavily (nghiên cứu công ty)
- Tài khoản Google (Sheets và Gmail)
- Google Sheets (lưu kết quả)
Chi phí
- Google Custom Search Engine: Miễn phí (100 tìm kiếm/ngày)
- OpenAI API: ~0.01-0.05 USD mỗi lead
- Apify: 39 USD/tháng (bao gồm LinkedIn scraping)
- Tavily: Miễn phí 1.000 lần tìm đầu tiên
- n8n: Có gói free, Pro từ 20 USD/tháng
Điều cần lưu ý
Bạn không cần biết lập trình, chỉ cần làm theo hướng dẫn và copy/paste cấu hình. Phần khó nhất là kết nối API, khi đã xong thì mọi thứ chạy mượt mà.
Ghi chú pháp lý
Hãy đảm bảo việc scrape LinkedIn tuân thủ điều khoản dịch vụ và quy định pháp luật địa phương. Giải pháp này phục vụ cho hoạt động tiếp cận khách hàng hợp pháp, không phải spam.
Các bước triển khai
Bước 1: Tạo Google Custom Search Engine
Điều này giúp bạn tìm hồ sơ LinkedIn thay vì toàn bộ internet.
- Vào Google Custom Search Engine
- Bấm “Add” để tạo công cụ tìm kiếm mới
- Trong “Sites to search”, nhập:
linkedin.com/in - Đặt tên “LinkedIn Profile Search”
- Bấm “Create”
- Ghi lại Search Engine ID
- Vào Google Cloud Console
- Bật Custom Search JSON API
- Tạo credentials và lấy API Key
Tại sao quan trọng: Nếu không, bạn sẽ tìm cả internet thay vì chỉ LinkedIn.
Bước 2: Tạo các tài khoản API cần thiết
OpenAI:
- Đăng ký tại OpenAI
- Thêm phương thức thanh toán
- Vào mục API Keys
- Tạo key mới và lưu an toàn
Apify:
- Đăng ký tại Apify
- Mua gói 39 USD/tháng
- Lấy API token trong Settings → Integrations
Tavily:
- Đăng ký tại Tavily
- Lấy API key miễn phí trong dashboard
- Bạn có 1.000 lần tìm free ban đầu
Bước 3: Tạo Google Sheet
- Tạo sheet mới tên “LinkedIn Lead Database”
- Hàng 1 tạo các cột:
nameurlemaillinkedin summarycompanylinkedin outreachcompany overviewcompany emailscrape complete?Email OutreachCampaign Name
- Lấy Google Sheet ID trong URL
Bước 4: Import workflow vào n8n
- Copy toàn bộ file JSON
- Trong n8n, bấm “+” → New workflow
- Menu ba chấm → “Import from Clipboard”
- Paste JSON và Import
Bước 5: Cấu hình kết nối
- Google Sheets: kết nối OAuth2, nhập Sheet ID
- OpenAI: nhập API Key vào node
- Apify: thêm token vào header “Authorization”
- Google Custom Search: nhập API key và Search Engine ID
- Tavily: nhập API key vào header
Bước 6: Test từng phần
Ví dụ test form:
- Campaign Name: Test Run 1
- Keywords: Marketing Director
- Location: New York
- Profiles: 5
Kết quả: Hệ thống tìm profile, scrape, nghiên cứu công ty và tạo tin nhắn.
Cấu hình chi tiết
- Search Parameters:
site:linkedin.com/in {jobTitle} {industry} {location} - AI Model: GPT-4.1-mini (tiết kiệm chi phí)
- Batch: 10 profiles/lần (có thể chỉnh)
- Company Research: Tavily ở chế độ “advanced”
Kiểm thử & thành công
- Dữ liệu đầy đủ trong Google Sheet
- Gmail tạo draft email cá nhân hóa
- Không báo lỗi trong log n8n
Do’s & Don’ts
✅ Nên: bắt đầu nhỏ, theo dõi chi phí API, kiểm tra email trước khi gửi, đặt tên campaign rõ ràng, backup sheet, kiểm tra deliverability.
❌ Không nên: bỏ qua rate limit, dùng tên campaign chung chung, xử lý batch lớn ngay, spam, bỏ qua bước cá nhân hóa thêm.
Troubleshooting
- Không tìm thấy LinkedIn URL → kiểm tra API key / query
- Lỗi scrape Apify → kiểm tra token / gói hết hạn
- Lỗi AI → kiểm tra credit OpenAI
- Sheets Permission denied → reconnect OAuth2
- Không có dữ liệu công ty → Tavily hết credit / tên công ty sai
- Trùng lặp → kiểm tra tên campaign
FAQ
- Chi phí: 0.1 – 0.5 USD mỗi lead (ngoài 39 USD/tháng Apify)
- Số lead/ngày: Free Google Search giới hạn 100, trả phí sẽ cao hơn
- Email thiếu: 60-70% có email, còn lại dùng email công ty
- Có thể tùy chỉnh nội dung không? Có, chỉnh prompt OpenAI
- Có hợp pháp không? Scraping ở vùng “xám”, cần xem TOS LinkedIn
- Tốc độ: 20-30 giây/profile
- Nếu LinkedIn chặn? Apify xử lý hầu hết, nếu vẫn lỗi → giảm batch, tăng delay
- Ngành khác ngoài AI consulting? Có thể, chỉ cần chỉnh nội dung AI prompt
- Tại sao nhiều dịch vụ? Mỗi cái chuyên 1 việc, ghép lại cho kết quả tốt hơn
- Muốn scale? Nâng Google Search trả phí, OpenAI tier, chạy nhiều campaign song song
Triết lý Kiến trúc (Architecture Philosophy)
Cỗ máy tìm khách hàng LinkedIn của bạn hoạt động như một pipeline nhiều tầng có trạng thái (stateful, multi-stage) chứ không phải một chuỗi tuyến tính đơn giản. Hãy hình dung nó như một dây chuyền sản xuất, trong đó mỗi trạm đều có bộ nhớ, kiểm soát chất lượng và khả năng xử lý đầu vào khác nhau. Thiết kế này giúp hệ thống vừa bền bỉ vừa hiệu quả.
Kiến trúc luồng dữ liệu (Data Flow Architecture)
Lớp nhập liệu: Xử lý ưu tiên trí tuệ (Intelligence-First Processing)
Hệ thống khởi động bằng một form trigger, nhưng ngay lập tức dùng AI để phân tích tiêu chí tìm kiếm. Thay vì chỉ truyền text thô, node OpenAI sẽ phân tích "software company founder in Chicago" thành dữ liệu có cấu trúc:
jobTitle: “software company founder”companyIndustry: “software”location: “Chicago”profilesToScrape: số lượng được trích xuất
Cách này ngăn chặn lỗi “rác vào → rác ra” (garbage-in-garbage-out) vốn hay gặp ở các automation đơn giản.
Quản lý trạng thái: Hệ thống loại trừ trùng lặp thông minh (Smart Deduplication)
Automation duy trì trạng thái qua Google Sheets theo cách rất tinh vi:
- Kiểm tra dữ liệu có sẵn: Trước khi gọi API tốn phí, hệ thống query sheet để lấy tập URL đã xử lý. Thực hiện trong node “Build Existing Set”.
- Logic phân trang: Node “Code1” tính toán điểm bắt đầu tìm kiếm. Ví dụ đã có 47 profile → sẽ tìm từ index 50 thay vì 1. Nhờ đó tránh xử lý lại và tiết kiệm API.
- Theo dõi tiến độ: Mỗi profile có cờ “scrape complete?”, cho phép tiếp tục campaign dang dở mà không mất dữ liệu.
Lớp tìm kiếm & khám phá (Search and Discovery Layer)
Google Custom Search được triển khai thông minh hơn bạn tưởng:
- Tạo query động: Kết hợp tiêu chí tìm kiếm với toán tử site của LinkedIn:
site:linkedin.com/in {jobTitle} {industry} {location} - Phân trang thông minh: Tính toán số trang kết quả cần dựa trên số profile yêu cầu, fetch theo lô 10.
- Lọc theo thời gian thực: Node “Code” loại bỏ URL đã có trong database, giúp bạn chỉ tốn phí scrape Apify cho profile mới.
Điều phối xử lý (Processing Orchestration)
Kiến trúc đa vòng lặp (Multi-Loop Architecture)
- Vòng lặp ngoài (Loop Over Items2): xử lý các LinkedIn URL mới để scrape profile.
- Vòng lặp trong (Loop Over Items7): nghiên cứu công ty cho mỗi profile scrape thành công.
Nhờ tách biệt, nếu scraping lỗi thì nghiên cứu công ty của profile khác vẫn tiếp tục.
Xử lý bất đồng bộ với trạng thái chờ
Node “Wait5” (delay 10 giây) xử lý việc Apify scrape bất đồng bộ. Hệ thống submit job → chờ → lấy kết quả. Tránh lỗi “lấy dữ liệu khi chưa sẵn sàng”.
Tổng hợp & xử lý theo lô
Node “Aggregate” gom nhiều dữ liệu trước khi gửi đến AI. Điều này vừa tiết kiệm chi phí API vừa cho AI nhìn thấy pattern trên nhiều profile cùng lúc.
Các tầng trí tuệ (Intelligence Layers)
Lớp AI chính: Phân tích hồ sơ
Node “Basic LLM Chain” xử lý dữ liệu LinkedIn scrape bằng prompt tinh vi để trích xuất:
- Tóm tắt nghề nghiệp: vai trò hiện tại, chuyên môn liên quan
- Góc tiếp cận: công nghệ, dự án, mục tiêu phù hợp dịch vụ bạn
- Điểm kết nối độc đáo: yếu tố riêng biệt để cá nhân hóa
Lớp AI thứ cấp: Agent nghiên cứu công ty
Node “AI Agent” dùng Tavily để:
- Ưu tiên nội dung từ website chính thức
- Tìm tin tức, thông cáo gần đây
- Lấy sentiment từ site review bên thứ ba
- Thu thập email công ty dự phòng
Lớp AI thứ ba: Tổng hợp thông điệp
Node “Basic LLM Chain3” kết hợp insight LinkedIn + nghiên cứu công ty để tạo thông điệp tiếp cận ngữ cảnh. Nó được lập trình để tìm “móc câu mạnh nhất” từ dữ liệu.
Xử lý lỗi & khả năng phục hồi (Error Handling and Resilience)
Xử lý có điều kiện
Node “If” phân nhánh logic: nếu profile có email cá nhân hoặc email công ty → tạo message; nếu không → đánh dấu “no email found” và đi tiếp.
Giảm thiểu lỗi (Graceful Degradation)
- Lỗi scrape LinkedIn → profile đánh dấu incomplete, không xóa
- Lỗi nghiên cứu công ty → vẫn tạo message dựa trên dữ liệu LinkedIn
- Lỗi tạo email → dữ liệu thô vẫn được lưu trong sheet
Phục hồi trạng thái
Do có cờ tiến độ, hệ thống có thể resume campaign dở. Nếu đang xử lý 100 profile và dừng ở giữa, restart sẽ tiếp tục từ chỗ cũ.
Tối ưu hiệu suất (Performance Optimization)
Giới hạn tốc độ thông minh
Hệ thống phân tán call API qua nhiều dịch vụ, thêm delay có kiểm soát → tránh bị block vì spam.
Chiến lược xử lý theo lô
- Google search theo batch
- LinkedIn scrape theo nhóm
- Gom dữ liệu trước khi AI xử lý
- Company research chạy song song khi có thể
Quản lý bộ nhớ
Node code dùng cấu trúc dữ liệu tối ưu (Set để loại trùng, filter chiến lược) → xử lý dataset lớn mà không tốn nhiều tài nguyên.
Bảo mật & quyền riêng tư dữ liệu
Quản lý credentials
API key được lưu trong credential system của n8n, không hardcode. Có thể share workflow mà không lộ thông tin nhạy cảm.
Kiểm soát lưu trữ dữ liệu
Dữ liệu scrape lưu trong Google Sheet cá nhân của bạn, không qua bên thứ ba. Bạn toàn quyền quản lý retention và quyền truy cập.
Dấu vết kiểm toán (Audit Trail)
Hệ thống tạo log đầy đủ: dữ liệu nào, xử lý lúc nào → dễ theo dõi và tuân thủ quy định.
Điểm tích hợp & phụ thuộc
Chuỗi phụ thuộc chính (Critical Path)
Google Custom Search → URL profile → Apify scrape → AI phân tích.
Nếu đứt một chỗ, batch đó dừng.
Cơ hội xử lý song song
- Form + kiểm tra dữ liệu cũ chạy cùng lúc
- Nghiên cứu công ty tách biệt với phân tích LinkedIn
- Google Sheets update song song với tạo email draft
Vòng phản hồi (Feedback Loops)
- Phát hiện trùng lặp → điều chỉnh phân trang tìm kiếm
- Trạng thái xử lý → quản lý campaign
- Lỗi → kích hoạt nhánh xử lý thay thế
Nền tảng Hệ thống (Platform Foundation)
N8N – Nền tảng Tự động hóa Workflow
Lý do chọn: n8n đóng vai trò “bộ điều phối” kết nối tất cả các dịch vụ khác. Khác với Zapier hay Make, n8n cho phép xây dựng logic phức tạp với code node, xử lý lỗi nâng cao và thao tác dữ liệu linh hoạt.
Yêu cầu tài khoản:
- Gói Free: hỗ trợ tối đa 5,000 workflow/tháng
- Gói Pro ($20/tháng): phù hợp triển khai thực tế với giới hạn cao hơn
- Có thể tự host để toàn quyền kiểm soát
Thông số kỹ thuật:
- Hơn 400+ tích hợp sẵn
- Hỗ trợ code JavaScript cho logic tùy chỉnh
- Giao diện kéo thả trực quan, có công cụ debug
- Webhook triggers cho xử lý real-time
Điểm lưu ý khi setup:
- Bản Cloud và bản Self-hosted có khác biệt về số lượng node
- Một số tính năng enterprise chỉ có ở tier cao hơn
- Free tier giới hạn thời gian chạy workflow (2 phút/workflow)
Vì sao không dùng công cụ khác:
- Zapier: không xử lý được JavaScript logic phức tạp
- Make: giới hạn về xử lý lỗi và nhánh điều kiện
- Microsoft Power Automate: đắt hơn, ít linh hoạt với logic tùy chỉnh
Lớp Tìm kiếm & Khám phá (Search and Discovery Layer)
Google Custom Search Engine + JSON API
Lý do chọn: Tìm kiếm của LinkedIn bị giới hạn, không cho phép tự động hóa. Google có chỉ mục LinkedIn đầy đủ, hợp pháp và hiệu quả.
Yêu cầu tài khoản:
- Google Cloud Platform (gói free có $300 credit)
- Tạo Custom Search Engine (miễn phí)
- Bật JSON API trong Google Cloud Console
Chi phí:
- 100 lượt tìm/ngày miễn phí
- Sau đó: $5 cho mỗi 1,000 truy vấn
- Không phí khởi tạo hoặc phí duy trì hàng tháng
Thông số kỹ thuật:
- Trả tối đa 10 kết quả mỗi request
- Hỗ trợ tìm kiếm theo domain (
site:linkedin.com/in) - Trả về JSON có metadata
- Có phân trang cho kết quả lớn
Yêu cầu cấu hình:
- Search Engine ID (ví dụ:
017576662512468239146:omuauf_lfve) - API Key đã bật quyền Custom Search JSON API
- Query phải được format chính xác để ra profile LinkedIn
Bước cài đặt quan trọng:
- Tạo Custom Search Engine tại https://cse.google.com/
- Chỉ thêm
linkedin.com/invào danh sách tìm kiếm - Bật JSON API trong Google Cloud Console
- Tạo API Key đúng scope
- Test query thủ công trước khi đưa vào workflow
Lỗi thường gặp:
- API key chưa bật Custom Search
- Sai Search Engine ID
- Vượt hạn mức tìm/ngày (rất dễ khi test)
- Query chưa chuẩn nên ra kết quả ngoài LinkedIn
Lớp Trích xuất Dữ liệu (Data Extraction Layer)
Apify LinkedIn Profile Scraper
Lý do chọn: Scraping trực tiếp LinkedIn rất khó do hệ thống chống bot. Apify duy trì sẵn một scraper chuyên nghiệp để xử lý phần này.
Yêu cầu tài khoản:
- Gói trả phí (tối thiểu $39/tháng)
- Không có gói free cho scraping LinkedIn
- Có gói enterprise cho nhu cầu lớn
Khả năng kỹ thuật:
- Trích xuất đầy đủ dữ liệu: kinh nghiệm, học vấn, kỹ năng
- Vượt qua cơ chế anti-bot & dynamic loading của LinkedIn
- Trả về JSON chuẩn, field name đồng nhất
- Có sẵn rate limit & retry logic
Chi tiết API:
- Actor ID:
2SyF0bVxmgGr8IVCZ(hardcode trong workflow) - Xác thực qua Bearer Token
- Xử lý bất đồng bộ (submit job → chờ → lấy kết quả)
- Output theo dataset
Đặc tính hoạt động:
- 10-30 giây/profil
- Tỉ lệ thành công: ~85-90% (một số profile private)
- Có rate limit tích hợp sẵn
- Dữ liệu cập nhật theo thời gian thực
Chi phí:
- $39/tháng đã bao gồm quota đáng kể
- Thêm phí theo số profile scrape
- Rẻ hơn nhiều so với tự xây scraper
- Bao gồm bảo trì & update chống phát hiện
Giải pháp thay thế:
- Phantombuster: tương tự về giá nhưng khác tính năng
- Tự viết scraper: tốn công phát triển & bảo trì
- Làm thủ công: không thể scale
Lớp Xử lý Thông minh (Intelligence Processing Layer)
OpenAI API Integration
Lý do chọn nhiều model: Mỗi nhiệm vụ khác nhau sẽ dùng model khác nhau để tối ưu chi phí & chất lượng.
Chiến lược chọn model:
- GPT-4.1-mini: phân tích query, xử lý đơn giản (rẻ hơn)
- GPT-4.1: phân tích profile phức tạp, tạo email (chất lượng cao hơn)
- Chi phí mỗi lead: khoảng $0.01 – $0.05 (tùy độ phức tạp)
Yêu cầu tài khoản:
- Tài khoản OpenAI Platform (khác ChatGPT)
- Phương thức thanh toán (nên nạp trước credits)
- API Key với quota phù hợp
- Hiểu rõ cách tính token
Sử dụng token trung bình:
- Query parsing: 200-500 token
- Phân tích profile: 1,500-3,000 token
- Tạo email: 800-1,500 token
- Tổng hợp công ty: 1,000-2,000 token
Giới hạn:
- Free: 200 request/ngày, 40,000 token/phút
- Paid: quota cao hơn theo lịch sử sử dụng
- Workflow có delay sẵn để tránh bị block
- Batch processing giúp tiết kiệm token
Cân đối chất lượng – chi phí:
- GPT-4: phân tích tốt, nhưng đắt
- GPT-3.5: nhanh & rẻ hơn, nhưng kém chi tiết
- Workflow cân bằng tùy nhiệm vụ
Lớp Nghiên cứu & Làm giàu Dữ liệu (Research and Enrichment Layer)
Tavily Search API
Lý do chọn: Scraping web để nghiên cứu công ty vừa kém ổn định vừa rủi ro pháp lý. Tavily là API tìm kiếm được thiết kế riêng cho AI agents & business intelligence.
Khả năng nổi bật:
- Kết quả tối ưu AI, có điểm relevance
- Trả dữ liệu dạng structured, dễ automation
- Dữ liệu web thời gian thực, kèm nguồn gốc
- Có bộ lọc nội dung & tóm tắt sẵn
Tài khoản:
- Free: 1,000 search/tháng
- Paid: từ $50/tháng
- Không bị rate limit như scraping truyền thống
- Có lựa chọn độ sâu tìm kiếm
Chiến lược sử dụng AI Agent:
- Ưu tiên website chính thức công ty
- Thứ cấp: review từ bên thứ ba (G2, Capterra, Reddit)
- Tìm email chung từ trang Contact
- Ưu tiên tin tức 12-18 tháng gần đây
Output:
- JSON có source attribution
- Tự động tóm tắt content dài
- Phân tích sentiment từ review
- Giữ link để xác thực
Lớp Lưu trữ & Quản lý Dữ liệu (Data Storage and Management)
Google Sheets
Vì sao không dùng database: Sheets đủ cấu trúc, dễ truy cập, dễ cộng tác cho team sales. Người không rành kỹ thuật cũng thao tác được.
Thiết kế schema:
- Nhận diện:
name,url(tracking, deduplication) - Liên hệ:
email,company email - Thông tin:
linkedin summary,company overview - Outreach:
linkedin outreach,email outreach - Quản lý campaign:
campaign name,scrape complete?
Tính năng nâng cao:
- Cập nhật điều kiện: appendOrUpdate để tránh trùng
- Query lọc: tìm record chưa hoàn tất
- Cập nhật theo URL match
- Tolerant lỗi (không crash toàn workflow)
Bảo mật:
- OAuth2 để truy cập an toàn
- Không hardcode credentials
- Phân quyền chi tiết (read/write, sheet cụ thể)
- Chia sẻ team dễ dàng qua Google Sheets
Lớp Giao tiếp (Communication Layer)
Gmail Integration
Lý do chọn Gmail: Thông dụng, API mạnh, tài liệu đầy đủ. Việc tạo draft thay vì gửi trực tiếp giúp team kiểm duyệt trước.
Chiến lược tạo draft:
- Sinh subject tự động
- Ưu tiên email cá nhân, fallback sang email công ty
- Lưu lại tất cả draft để chỉnh sửa
- Tích hợp workflow Gmail sẵn có
Xác thực:
- OAuth2 để bảo mật
- Gmail API với scope tạo draft
- Credential tách riêng với Google Sheets
Điều kiện Kỹ thuật & Yêu cầu sâu hơn
Quản lý API Key
Best practices:
- Không hardcode key trong workflow JSON
- Luôn dùng credential system của n8n
- Thường xuyên rotate key (nhất là sau khi share workflow)
- Giám sát usage để phát hiện bất thường
Tổ chức:
- Tạo account API riêng cho automation
- Đặt tên credential dễ nhận diện
- Document rõ ràng key nào dùng cho service nào
- Bật cảnh báo billing để tránh phát sinh ngoài ý muốn
Kế hoạch dung lượng & chi phí
Pattern thực tế:
- Nhỏ (10-50 lead): $5-15 API cost
- Vừa (100-200 lead): $25-50
- Lớn (500+ lead): $75-150
- Hoạt động thường xuyên: $200-500/tháng
Lưu trữ:
- Sheets: giới hạn 10 triệu cell (rất khó chạm tới)
- n8n history: hạn chế với free tier
- Gmail draft: gần như không giới hạn
- API caching: xử lý tự động
Hạ tầng mạng & hiệu suất
- Băng thông: rất thấp (JSON API call)
- Độ nhạy trễ: trung bình (workflow đã có delay sẵn)
- Xử lý song song: giới hạn bởi rate limit API, không phải hệ thống
- Thời gian xử lý: 15-30 phút/50 lead, tăng tuyến tính
Compliance & Pháp lý
Bảo mật dữ liệu:
- Tuân thủ GDPR nhờ hạ tầng Google
- Dữ liệu do bạn kiểm soát & xoá bất cứ lúc nào
- Có quyền “xóa dữ liệu” qua Google Sheets
- Cơ sở pháp lý xử lý: lợi ích kinh doanh hợp pháp
Điều khoản dịch vụ:
- LinkedIn: vùng xám (Apify xử lý compliance)
- Google: API hợp lệ cho use case này
- OpenAI: cho phép dùng business
- Tavily: thiết kế riêng cho BI use case
Phương pháp Chẩn đoán (Diagnostic Methodology)
Khung phương pháp LOCATE
Khi automation gặp lỗi, hãy dùng quy trình có hệ thống này:
L – Logs (Nhật ký): Kiểm tra n8n execution history trước tiên
O – Output (Đầu ra): Xem kỹ mỗi node thực sự tạo ra dữ liệu gì
C – Credentials (Thông tin xác thực): Xác minh tất cả kết nối API đang hoạt động
A – APIs: Kiểm tra tình trạng sẵn sàng của dịch vụ bên ngoài
T – Timing (Thời gian): Xem có bị rate limit hay timeout không
E – Environment (Môi trường): Xác nhận định dạng dữ liệu và các phụ thuộc
Cách này giúp tránh thói quen đoán mò rồi sửa bừa.
Cách đọc Execution Logs của n8n
Xem ở đâu: Nhấp vào một execution trong lịch sử workflow, sau đó nhấp vào từng node để xem input/output.
Cần xem gì:
- Node màu đỏ: Lỗi hoàn toàn, có thông báo lỗi
- Node màu vàng: Cảnh báo hoặc lỗi một phần
- Đầu ra rỗng: Node đã chạy nhưng không tạo dữ liệu
- Sai lệch định dạng dữ liệu: Đầu ra không khớp với kỳ vọng của node kế tiếp
Mẹo: Thông tin hữu ích nhất thường nằm trong JSON output của node ngay trước node bị lỗi.
Nhóm 1: Lỗi Thiết lập ban đầu & Cấu hình
Vấn đề: “Import workflow xong nhưng không chạy được”
Triệu chứng: Bấm Execute không có gì xảy ra, hoặc lỗi ngay lập tức trước khi bất kỳ node nào chạy
Nguyên nhân gốc: Credentials thiếu hoặc cấu hình sai
Các bước chẩn đoán:
- Vào trang Credentials trong phần cài đặt n8n
- Kiểm tra tất cả credentials cần thiết đang ở trạng thái “Connected”
- Test từng credential một
- Xác minh các node thực sự đang dùng đúng credentials (không chỉ tạo ra rồi bỏ đó)
Cách khắc phục:
- Xóa tất cả credentials hiện có
- Tạo lại từng credential và test
- Gán lại credentials cho tất cả node cần dùng
- Lưu và test workflow
Lưu ý thường gặp:
- OAuth hết hạn cần re-authorize
- API key gõ thừa khoảng trắng hoặc thiếu ký tự
- Chọn sai loại credential (OAuth2 vs API key)
Vấn đề: “Google Custom Search không trả kết quả”
Triệu chứng: Node HTTP Request thành công nhưng mảng items rỗng
Nguyên nhân gốc: Lỗi cấu hình tìm kiếm
Cách chẩn đoán:
- Kiểm tra CSE cấu hình đúng chưa
- Test tìm kiếm thủ công trên trình duyệt
- Xác minh API key có đủ quyền
- Kiểm tra hạn mức sử dụng trong ngày
Các bước sửa:
- Vào https://cse.google.com/ và test search engine của bạn
- Thử truy vấn:
software company founder chicago - Nếu không có kết quả → CSE cấu hình sai
- Nếu có kết quả nhưng API trả rỗng → vấn đề xác thực
- Kiểm tra Google Cloud Console: API đã bật và còn quota
Debug nâng cao:
- Dùng DevTools để xem request API chính xác gửi đi
- So sánh với ví dụ cURL chuẩn từ tài liệu Google
- Thử bằng các từ khóa đơn giản trước
Vấn đề: “Apify scraping thất bại ngay lập tức”
Triệu chứng: Node Apify trả lỗi hoặc luôn trả dữ liệu rỗng
Nguyên nhân gốc: Xác thực, gói thuê bao, hoặc sự cố dịch vụ
Quy trình xác minh:
- Test API Apify thủ công:
curl -H "Authorization: Bearer YOUR_TOKEN" https://api.apify.com/v2/acts - Kiểm tra trạng thái tài khoản & subscription trong dashboard Apify
- Xác minh actor ID
2SyF0bVxmgGr8IVCZkhả dụng với tài khoản của bạn - Test với một URL LinkedIn đã biết
Lộ trình khắc phục:
- Xác nhận gói trả phí Apify đang hoạt động
- Tạo token API mới nếu cần
- Test actor scraper cụ thể trong console của Apify
- Kiểm tra còn đủ credits sử dụng
Nhóm 2: Lỗi Luồng dữ liệu & Xử lý
Vấn đề: “Dữ liệu không truyền đúng giữa các node”
Triệu chứng: Node có input nhưng output sai, hoặc node kế tiếp lỗi
Nguyên nhân gốc: Giả định sai về cấu trúc dữ liệu hoặc mapping sai
Kỹ thuật chẩn đoán:
- Chạy từng node riêng lẻ (right-click → Execute Node)
- Soi kỹ cấu trúc JSON output
- So sánh định dạng mong đợi vs thực tế
- Kiểm tra tên trường trùng khớp (phân biệt hoa thường)
Lỗi luồng dữ liệu phổ biến:
Vấn đề: “Code node gọi các field không tồn tại”
Cách sửa:
- Xem cấu trúc input thực sự
- Cập nhật tham chiếu field trong code cho đúng
- Viết code phòng thủ cho field tùy chọn
// Sai: giả định field luôn tồn tại
const email = item.json.email;// Đúng: kiểm tra tồn tại nhiều khả năng
const email = item.json.email || item.json['Email Address'] || '';
Vấn đề: “Merge node tạo cấu trúc dữ liệu lạ”
Cách sửa:
- Hiểu rõ các chế độ merge (combine vs merge vs append)
- Kiểm tra chế độ merge hiện tại
- Xác minh thời điểm và tính sẵn sàng của dữ liệu input
- Test trước với dataset nhỏ
Vấn đề: “Form trigger hoạt động nhưng node sau không thấy dữ liệu form”
Triệu chứng: Gửi form thành công nhưng node sau không lấy được dữ liệu
Nguyên nhân gốc: Tham chiếu sai tên node trong code
Cách sửa:
- Xác định chính xác tên node trigger (phân biệt hoa thường)
- Cập nhật tất cả code node đang tham chiếu dữ liệu trigger
- Dùng cú pháp n8n chuẩn:
$('On form submission').first().json['Field Name'] - Test cú pháp tham chiếu riêng biệt
Mẫu debug code:
// Debug truy cập dữ liệu form
const triggerNode = $('On form submission').first();
console.log('Trigger node data:', JSON.stringify(triggerNode.json, null, 2));
console.log('Available fields:', Object.keys(triggerNode.json));
Nhóm 3: Lỗi Dịch vụ bên ngoài & API
Vấn đề: “Yêu cầu OpenAI lúc được lúc không”
Triệu chứng: Có profile xử lý được, có profile lỗi API
Nguyên nhân gốc: Rate limit, giới hạn token, hoặc content filtering
Chẩn đoán có hệ thống:
- Kiểm tra dashboard usage của OpenAI xem quota
- Đọc thông báo lỗi để biết loại lỗi cụ thể
- Test prompt đơn giản để cô lập vấn đề
- Theo dõi pattern tiêu thụ token
Chiến lược khắc phục:
- Rate limit: Thêm delay giữa các request hoặc nâng tier OpenAI
- Giới hạn token: Tối ưu prompt để dùng ít token hơn
- Content filtering: Rà dữ liệu profile có nội dung dễ bị chặn
- Tình trạng model: Chuyển sang model thay thế khi model chính bận
Phòng ngừa:
- Thiết lập cảnh báo billing trong dashboard OpenAI
- Theo dõi xu hướng dùng token
- Thêm mô hình dự phòng trong workflow
- Thêm retry logic với exponential backoff
Vấn đề: “Tavily trả thông tin không liên quan”
Triệu chứng: Phần nghiên cứu công ty bị lạc đề
Nguyên nhân gốc: Cấu trúc truy vấn tìm kiếm hoặc lọc kết quả
Cách debug:
- Test Tavily thủ công bằng API key của bạn
- Xem lại truy vấn đang tạo ra
- Kiểm tra tên công ty truyền vào có chính xác không
- Xác minh còn đủ credits Tavily
Cải thiện:
- Tăng độ cụ thể của truy vấn
- Thêm từ khóa loại trừ (negative keywords)
- Điều chỉnh độ sâu tìm kiếm theo chất lượng kết quả
- Áp dụng chấm điểm mức độ liên quan (relevance scoring)
Vấn đề: “Không tạo được draft Gmail”
Triệu chứng: Đã tạo nội dung outreach nhưng Gmail không có draft
Nguyên nhân gốc: Scope xác thực hoặc quyền truy cập
Quy trình sửa:
- Kiểm tra quyền Gmail API trong Google Cloud Console
- Xác nhận OAuth scope có quyền compose/tạo draft
- Test truy cập Gmail API thủ công
- Re-authenticate credential Gmail trong n8n
Nhóm 4: Lỗi Logic & Xử lý
Vấn đề: “AI tạo thông điệp chung chung/không liên quan”
Triệu chứng: Nội dung outreach thiếu cá nhân hóa dù dữ liệu profile tốt
Nguyên nhân gốc: Prompt chưa tối ưu hoặc thiếu ngữ cảnh
Khung phân tích:
- Rà dữ liệu input thực sự gửi vào AI nodes
- Kiểm tra scraping profile có đủ chi tiết không
- Đánh giá chất lượng nghiên cứu công ty
- Test prompt với dữ liệu “đẹp” đã biết
Quy trình cải thiện:
- Nâng cấp prompt với hướng dẫn cụ thể hơn
- Thêm ví dụ “tốt vs xấu” vào prompt
- Mở rộng ngữ cảnh bằng cách kết hợp nhiều nguồn dữ liệu
- Áp dụng chấm điểm chất lượng đầu ra
Vấn đề: “Phát hiện trùng lặp hoạt động không đúng”
Triệu chứng: Profile bị xử lý lặp lại hoặc profile mới hợp lệ bị bỏ qua
Nguyên nhân gốc: Chuẩn hóa URL hoặc logic so sánh
Các bước debug:
- Xem kỹ logic trong “Build Existing Set”
- Kiểm tra tính thống nhất URL (dấu gạch chéo cuối, hoa/thường)
- Xác minh tên campaign khớp tuyệt đối
- Test với các case duplicate đã biết
Sửa code:
// Chuẩn hóa URL tốt hơn
const normalizedURL = item.json.url.trim().toLowerCase().replace(//+$/, ''); // Bỏ dấu / ở cuối
Vấn đề: “Workflow chạy xong nhưng chất lượng kết quả kém”
Triệu chứng: Kỹ thuật ổn nhưng không hiệu quả kinh doanh: tỉ lệ phản hồi thấp, prospect không phù hợp
Nguyên nhân gốc: Tiêu chí tìm kiếm/targeting chưa chuẩn
Cách tối ưu:
- Rà lại từ khóa tìm kiếm đủ cụ thể chưa
- Phân tích loại profile đang được tìm thấy
- Tinh chỉnh location & job title
- A/B test nhiều cách tìm kiếm khác nhau
Nhóm 5: Hiệu năng & Mở rộng
Vấn đề: “Workflow timeout hoặc chạy rất chậm”
Triệu chứng: Thời gian chạy dài, lỗi timeout, xử lý không hoàn tất
Nguyên nhân gốc: Batch chưa tối ưu, rate limit, hoặc giới hạn tài nguyên
Phân tích hiệu năng:
- Xem thời gian thực thi của từng node
- Xác định nút thắt cổ chai trong luồng dữ liệu
- Rà thời gian phản hồi của các API
- Theo dõi tài nguyên n8n sử dụng
Chiến lược tối ưu:
- Giảm kích thước batch ở giai đoạn đầu
- Thêm wait node chiến lược để tôn trọng rate limit
- Tận dụng xử lý song song khi có thể
- Nâng gói n8n nếu chạm giới hạn thực thi
Vấn đề: “Chi phí API cao nhưng giá trị thu được không tương xứng”
Triệu chứng: Hóa đơn API đắt nhưng lead kém chất lượng hoặc chuyển đổi thấp
Nguyên nhân gốc: Dùng API chưa hiệu quả hoặc targeting kém
Quy trình tối ưu chi phí:
- Audit mức dùng API trên tất cả dịch vụ
- Loại bỏ call không cần thiết/ trùng lặp
- Tối ưu prompt để giảm token
- Cải thiện targeting tìm kiếm để giảm xử lý lãng phí
Kỹ thuật Chẩn đoán Nâng cao
Kiểm thử từng node (Node-by-Node)
Khi vấn đề phức tạp, hãy test từng thành phần độc lập:
- Form trigger: Gửi dữ liệu test và xác minh định dạng output
- OpenAI parsing: Test input đã biết, kiểm tra trích xuất tham số
- Google search: Test query thủ công và so sánh kết quả
- Apify scraping: Gửi 1 URL LinkedIn và xác minh dữ liệu
- AI analysis: Test với dữ liệu profile đã biết, đánh giá chất lượng
- Company research: Test với tên công ty đã biết
- Message generation: Test với bộ dữ liệu đầy đủ
Xác thực cấu trúc dữ liệu
Các lỗi cấu trúc thường gặp & cách sửa:
Nhầm giữa Array và Object:
// Kiểm tra kiểu dữ liệu
console.log('Data type:', Array.isArray($input.all()) ? 'Array' : 'Object');
console.log('Item count:', $input.all().length);
Không thống nhất tên field:
// Debug các field sẵn có
const item = $input.first().json;
console.log('Available fields:', Object.keys(item));
console.log('Field values:', JSON.stringify(item, null, 2));
Kiểm tra tình trạng dịch vụ bên ngoài
Trước khi kết luận workflow hỏng, hãy kiểm tra tình trạng các dịch vụ:
- OpenAI status: https://status.openai.com/
- Google APIs: https://status.cloud.google.com/
- Apify status: Xem dashboard thông báo dịch vụ
- Tavily status: Test API thủ công bằng truy vấn đơn giản
Nhận diện mẫu lỗi (Error Pattern)
- Lỗi gián đoạn: Thường do rate limit hoặc sự cố tạm thời
- Lỗi lặp lại nhất quán: Cấu hình hoặc xác thực sai
- Suy giảm dần: Dấu hiệu sắp chạm quota
- Chất lượng dữ liệu ngẫu nhiên: Có thể do nguồn dữ liệu gốc
Quy trình Khôi phục & Reset
Khi nào Reset và khi nào Debug
Reset ngay nếu:
- Nhiều node báo lỗi credential
- Cấu trúc workflow có dấu hiệu hỏng
- Định dạng dữ liệu sai lệch hoàn toàn
- Xuất hiện hơn 3 loại lỗi khác nhau cùng lúc
Debug dần nếu:
- Chỉ một node/dịch vụ lỗi
- Lỗi chất lượng dữ liệu (có thể do prompt)
- Lỗi hiệu năng (có thể tối ưu)
- Lỗi gián đoạn có thể do tạm thời
Quy trình Reset sạch
- Export cấu hình đang chạy ổn (nếu có phần nào ổn)
- Ghi lại cấu hình tùy chỉnh (API keys, sheet IDs, prompt)
- Xóa execution history trong n8n
- Xóa & tạo lại credentials có vấn đề
- Re-import workflow từ JSON gốc
- Cấu hình lại theo ghi chú
- Test với dữ liệu tối thiểu trước
Chiến lược Backup & Khôi phục
Nên backup định kỳ:
- File JSON export của workflow n8n
- Google Sheet ID & cấu trúc sheet
- Prompt đã chỉnh sửa
- Tài liệu API keys
- Ghi chú cấu hình đang hoạt động
Thời điểm backup:
- Sau khi setup thành công ban đầu
- Trước khi thay đổi lớn
- Hàng tuần trong giai đoạn sử dụng tích cực
- Trước khi nâng cấp dịch vụ bên ngoài
Mấu chốt: Đây là một hệ thống phức tạp; các lỗi cấu hình nhỏ có thể gây hiệu ứng domino. Chẩn đoán có hệ thống và test từng phần riêng lẻ sẽ giải quyết 95% vấn đề nhanh hơn nhiều so với cố “sửa tất cả cùng lúc”.
Liên hệ tư vấn chuyên sâu theo yêu cầu
- Tận dụng sàn thương mại điện tử để xây dựng thương hiệu
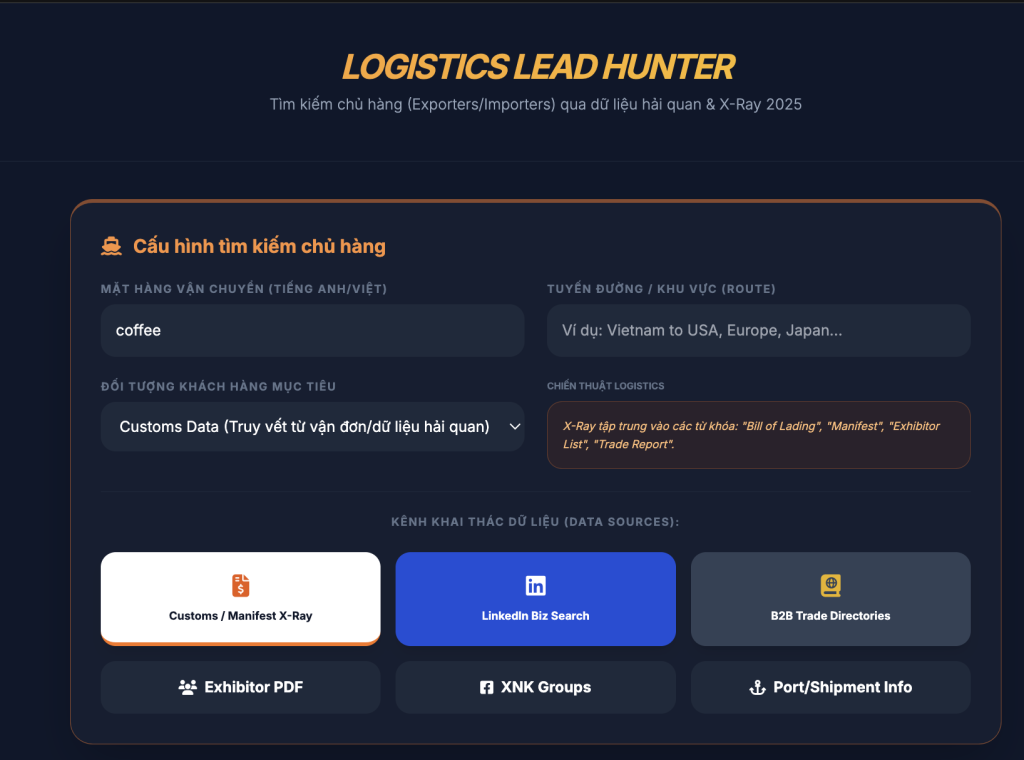
- AI Automation – Tự Động Hóa Quy Trình Logistics
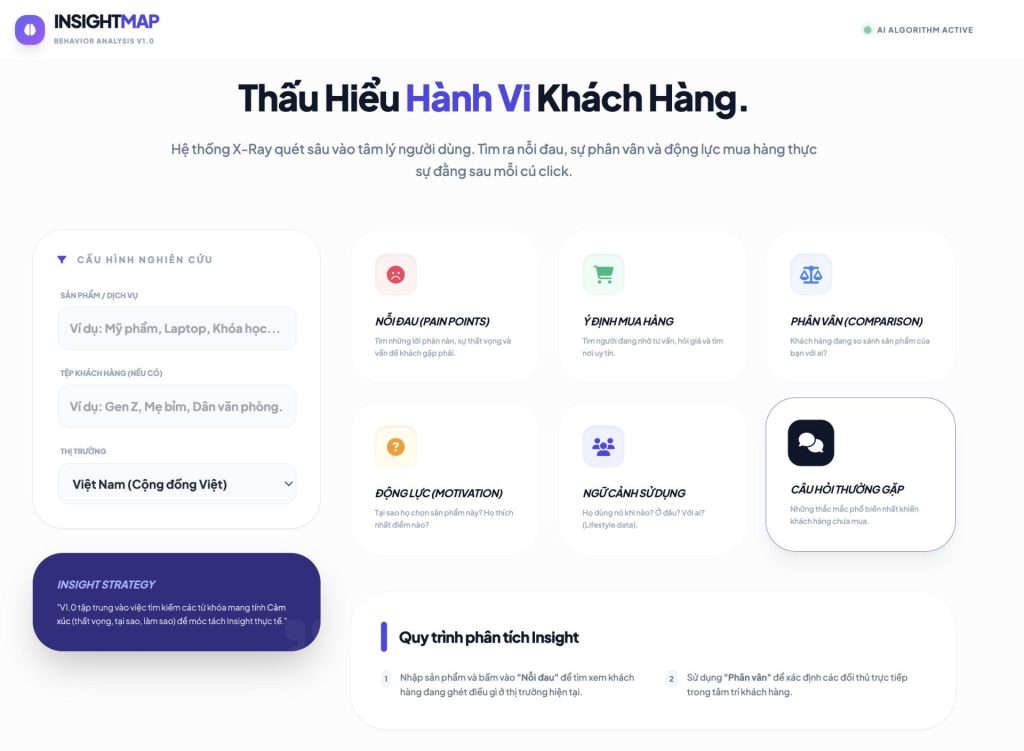
- Protected: AI Phân tích Persona
- AI Automation – Tổng hợp báo cáo tài chính hằng tháng
- AI Automation – Tự động quét tin doanh nghiệp trước cuộc gọi: Workflow hỗ trợ Sales chuẩn bị thông tin mỗi ngày