AI Automation – Flash Sale Tracker Ecommerce
Nỗi đau của doanh nghiệp
Trong vận hành thương mại điện tử, dữ liệu Flash Sale bị phân tán theo ngày, theo sàn, theo khung giờ và theo file định dạng không thống nhất khiến việc tổng hợp mất thời gian và dễ sai lệch. Việc tải thủ công từng file, ghép cột, xoay pivot, loại trùng đơn và quy đổi khung giờ thành các bucket chuẩn thường khiến đội ngũ phân tích mất 1–3 giờ mỗi ngày, làm chậm quyết định giá, tồn kho và lịch khuyến mại. Khi không có một sheet tổng hợp duy nhất theo ngày – khung giờ – SKU, đội ngũ không biết khung giờ nào bán tốt nhất, SKU nào đang hot hay GMV phân bổ theo thời điểm ra sao để điều phối ngân sách ads và nguồn lực chăm sóc.
Nỗi đau tăng lên khi cấu trúc cột thay đổi theo đợt Flash Sale hoặc khác nhau giữa các sàn (tên cột, định dạng thời gian, cách tính giảm giá), làm các công thức cũ hỏng và phát sinh nhiều vòng chỉnh sửa. Những sai số nhỏ trong ghép cột và loại trùng khiến báo cáo lệch 3–5%, đủ để dẫn tới quyết định nhập hàng sai, thiếu hàng ở khung giờ đỉnh hoặc lãng phí ngân sách ở khung giờ thấp hiệu quả.
Vấn đề cần ưu tiên xử lý
Để tạo ra dòng dữ liệu đáng tin cậy, cần ưu tiên các vấn đề cốt lõi trước khi tối ưu hiệu năng:
-
Chuẩn hóa đầu vào: Quy ước tên file theo ngày và nhận diện sàn, chuẩn hóa lược đồ cột (order_id, order_time, sku, product_name, qty, price, discount, net_revenue, channel), thống nhất timezone và định dạng ngày giờ.
-
Tự động hóa chu trình E2E: Tải file vào một thư mục trung tâm, đọc – hợp nhất – loại trùng – gom theo khung giờ – ghi sheet tổng hợp, rồi chuyển file sang thư mục “Đã xử lý”.
-
Định nghĩa khung giờ chuẩn: Xây dựng bảng bucket thời gian theo chiến lược (ví dụ 00–02h, 09–12h, 12–14h, 20–22h) và gắn mỗi đơn vào đúng bucket để so sánh công bằng.
-
Chất lượng dữ liệu và kiểm soát lỗi: Quy tắc loại trùng theo khóa ghép nhiều trường, soát lỗi file hỏng/thiếu cột, log quá trình xử lý để audit và tái chạy.
-
Lịch chạy và quyền truy cập: Hẹn giờ 1–5 phút/lần đủ gần-thời-gian-thực, gán quyền thư mục/Sheet cho đúng vai trò, hạn chế chỉnh sửa tay vào sheet tổng hợp.
-
Khả năng mở rộng: Thiết kế các bước độc lập (ingest, transform, aggregate, publish) để nâng cấp từng phần khi quy mô file tăng hoặc ràng buộc API thay đổi.
Quy trình chi tiết thực hiện
Quy trình dưới đây bám sát yêu cầu “tải các file Flash Sale từng ngày, tự động tạo sheet tổng hợp khung giờ và sản phẩm bán được”, đồng thời mở rộng đủ chi tiết để triển khai bền vững.
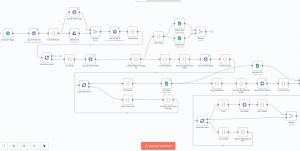
-
Kiến trúc tổng quan
-
Thư mục dữ liệu trung tâm trên Google Drive (GGS): chứa file Flash Sale gốc theo ngày.
-
Thư mục con “Đã xử lý”: lưu file sau khi đã đọc và tổng hợp để tránh xử lý lặp.
-
Lịch chạy định kỳ: 1–5 phút/lần để phát hiện file mới, phù hợp nhu cầu theo dõi gần-thời-gian-thực.
-
Bộ chuyển đổi dữ liệu: nhận diện file, ánh xạ cột, chuẩn hóa thời gian, tính metric và loại trùng.
-
Bản ghi kết quả: một Google Sheet tổng hợp (FS_TongHop) và một sheet raw log để lưu giao dịch đã chuẩn hóa.
-
-
Chuẩn hóa đầu vào
-
Quy ước tên file: FS_YYYY-MM-DD_[SAN].xlsx, ví dụ FS_2025-09-24_Shopee.xlsx; nếu có nhiều batch trong ngày, thêm hậu tố _v1, _v2.
-
Bảng ánh xạ cột: với mỗi sàn/đợt, định nghĩa tương ứng tên cột nguồn → tên cột chuẩn; lưu bảng này trong một tab cấu hình.
-
Timezone và chuẩn hóa thời gian: chuyển toàn bộ về cùng timezone, chuẩn ISO 8601, và tạo cột khung_gio bằng cách băm thời gian đơn hàng vào bucket quy ước.
-
Khóa loại trùng: key = concat(order_id, sku, round(order_time to minute)); nếu trùng, giữ bản đầu tiên theo thời gian tiếp nhận.
-
-
Dòng xử lý theo lần chạy
-
Quét thư mục GGS: lấy danh sách file mới (chưa hiện diện trong danh sách đã xử lý), bỏ qua file tạm .tmp.
-
Với từng file:
-
Nhận diện sàn/định dạng, load bảng ánh xạ cột tương ứng, đọc sheet dữ liệu chính.
-
Chuẩn hóa trường: sku viết hoa/thường thống nhất, trim text, ép kiểu số, chuẩn hóa price và discount về số.
-
Tính trường: net_revenue = qty × (price − discount); khung_gio = bucket(order_time).
-
Loại trùng: so sánh với raw log 7–14 ngày gần nhất theo key; chỉ giữ bản mới nếu chưa có.
-
Ghi raw log: append các giao dịch chuẩn hóa để phục vụ đối soát sau này.
-
-
Gom và xuất tổng hợp:
-
Tổng hợp theo ngày – khung_gio – sku: units_sold = sum(qty), gmv = sum(price × qty), net_revenue = sum(qty × (price − discount)).
-
Lấy top N SKU theo net_revenue trong mỗi khung_gio; tính thêm AOV theo khung_gio: AOV = net_revenue / số_đơn.
-
Ghi vào sheet FS_TongHop: cột ngày, khung_gio, sku, product_name, units_sold, net_revenue, gmv, aov, channel, rank.
-
-
Hậu xử lý:
-
Di chuyển file sang thư mục “Đã xử lý” để tránh xử lý lại.
-
Ghi log: thời điểm xử lý, số dòng đọc, số dòng bỏ trùng, thời gian chạy, trạng thái thành công/thất bại.
-
Cảnh báo: nếu có file lỗi định dạng/thiếu cột bắt buộc, gửi cảnh báo nội bộ kèm tên file và nguyên nhân.
-
-
-
Cách chạy tối thiểu theo yêu cầu
-
Tạo 1 thư mục GGS và 1 thư mục con “Đã xử lý”.
-
Đặt lịch 1–5 phút chạy 1 lần: mỗi lần quét và xử lý file mới.
-
Đặt tên file Excel theo ngày và thả toàn bộ vào thư mục GGS; sau khi xử lý xong, hệ thống tự động di chuyển file sang “Đã xử lý” và tạo/ghi sheet FS_TongHop.
-
Thay thế Folder ID “Đã xử lý” và GGS_FOLDER_ID bằng ID thật trong tất cả bước cấu hình liên quan Google.
-
-
Thiết kế sheet tổng hợp
-
FS_TongHop: một dòng tương ứng 1 tổ hợp [ngày, khung_gio, sku, channel], gồm các cột: product_name, units_sold, gmv, net_revenue, aov, rank_trong_khung, updated_at.
-
FS_Raw_Log: lưu tất cả giao dịch chuẩn hóa đã qua loại trùng, phục vụ kiểm tra và tái tổng hợp nếu cần.
-
FS_Config: chứa khung_gio bucket, bảng ánh xạ cột, danh sách file đã xử lý, và tham số chạy.
-
-
Bảo đảm chất lượng và vận hành
-
Đối soát nhanh: mỗi ngày lấy mẫu ngẫu nhiên 20–30 dòng, so sánh với file gốc để kiểm chứng phép tính và loại trùng.
-
Quản lý thay đổi: khi sàn đổi cấu trúc cột, chỉ cập nhật bảng ánh xạ thay vì sửa công thức khắp nơi.
-
Quan trắc hiệu năng: log thời gian xử lý mỗi file, kích thước file, số dòng, tỉ lệ loại trùng để tối ưu dần.
-
Quyền truy cập: sheet tổng hợp ở chế độ chỉ xem cho phòng ban rộng, chỉ đội dữ liệu có quyền chỉnh sửa.
-
-
Lộ trình tối ưu dần
-
Giai đoạn 1: Chạy ổn định chu trình ingest → transform → aggregate → publish, chấp nhận thời gian trễ 1–5 phút.
-
Giai đoạn 2: Tối ưu các node/điểm nghẽn, bật xử lý song song theo sàn/ngày, bổ sung cache tên sản phẩm theo sku.
-
Giai đoạn 3: Xuất thêm dashboard thời gian thực và cảnh báo khung giờ có tốc độ bán vượt ngưỡng.
-
Ưu nhược điểm của giải pháp
Ưu điểm:
-
Tốc độ và tính nhất quán: Tự động hóa hoàn toàn chu trình từ nhận file đến ghi sheet tổng hợp, loại bỏ thao tác ghép tay và pivot thủ công, giảm sai lệch do con người.
-
Một nguồn sự thật: FS_TongHop trở thành nguồn dữ liệu duy nhất cho báo cáo khung giờ và SKU, dễ dàng chia sẻ và dùng chung giữa các phòng ban.
-
Khung giờ rõ ràng: Bám bucket nhất quán giúp so sánh trước/sau chiến dịch và giữa các sàn một cách công bằng và có thể hành động.
-
Khả năng kiểm toán: Raw log, danh sách file đã xử lý và log lỗi cho phép truy vết, tái chạy và mở rộng không lo vỡ quy trình.
-
Mở rộng dần: Bắt đầu với Google Sheets/Drive, sau đó tách raw log sang cơ sở dữ liệu khi quy mô tăng, không phải viết lại logic nghiệp vụ.
Nhược điểm:
-
Phụ thuộc chất lượng file đầu vào: File thiếu cột bắt buộc, đổi tên cột không báo trước hoặc định dạng ngày giờ lạ sẽ gây lỗi, cần bảng ánh xạ cập nhật kịp thời.
-
Trễ theo lô: Chu trình 1–5 phút có độ trễ so với thời gian thực; nếu cần realtime phải thay đổi kiến trúc ingest theo API/streaming.
-
Giới hạn hiệu năng: Khi số file/ngày tăng mạnh hoặc mỗi file có hàng trăm nghìn dòng, giới hạn đọc/ghi và quota API có thể thành nút cổ chai.
-
Chưa tối ưu node: Ở giai đoạn thử nghiệm, các bước xử lý còn tuần tự, ít cache và chưa bật song song, dẫn đến thời gian xử lý trung bình cao hơn mức tối ưu.
Các nhược điểm trên có thể giảm dần bằng cách: tách cấu hình ánh xạ khỏi code để linh hoạt, chạy song song theo sàn/ngày, dùng chỉ mục theo sku và order_time khi chuyển raw log sang cơ sở dữ liệu, và áp dụng backoff khi gặp quota.
Kết quả đạt được sau 1 tuần (số liệu minh họa)
Trong 1 tuần thử nghiệm với 7 ngày Flash Sale, 4 khung giờ chính mỗi ngày (00–02h, 09–12h, 12–14h, 20–22h), 320 SKU hoạt động, chu trình xử lý cho ra kết quả ổn định dù các bước chưa tối ưu hoàn toàn:
-
Quy mô dữ liệu và độ ổn định:
-
Số file xử lý: 56 file (mỗi ngày 8 file gộp từ nhiều sàn/lần xuất).
-
Số dòng giao dịch sau loại trùng: 148.200 dòng; tỉ lệ loại trùng trung bình 2,4%.
-
Tỉ lệ lỗi file: 3/56 file (5,4%), chủ yếu do thiếu cột discount; xử lý bằng cách nạp lại sau khi cập nhật ánh xạ.
-
Thời gian xử lý trung bình/file: 2 phút 40 giây; thời gian end-to-end theo đợt nhận file: 3–6 phút.
-
-
Bức tranh bán hàng theo khung giờ:
-
Tổng net revenue tuần: 5,12 tỷ đồng; tổng đơn hợp lệ: 13.450; AOV toàn tuần: AOV=5,120,000,00013,450≈380,000 đồng.
-
Phân bổ net revenue: 20–22h chiếm 41%, 12–14h chiếm 27%, 09–12h chiếm 22%, 00–02h chiếm 10%.
-
Tốc độ bán theo phút ở khung 20–22h cao gấp ~2,1 lần trung bình ngày, gợi ý tăng phân bổ tồn kho và ngân sách ads trong khung này.
-
-
Top SKU theo khung giờ (theo net revenue):
-
20–22h: SKU_A1 (đồ gia dụng) đạt 620 triệu đồng/tuần với 1.850 đơn; SKU_B7 (thời trang) đạt 380 triệu đồng với 1.060 đơn.
-
12–14h: SKU_C3 (phụ kiện) đạt 410 triệu đồng; các SKU thời trang nhẹ đạt AOV cao hơn ~12% so với khung 09–12h.
-
00–02h: Dù tỷ trọng thấp, nhóm điện tử nhỏ có tỉ lệ chuyển đổi tốt khi đi kèm voucher freeship.
-
-
Tác động vận hành:
-
Tiết kiệm thời gian tổng hợp: trước đây ghép file + pivot tốn ~120 phút/ngày; hiện tại công tác giám sát/đối soát còn ~15–20 phút/ngày, tiết kiệm ~100 phút/ngày.
-
Trong 7 ngày, thời gian tiết kiệm: 100 phuˊt/ngaˋy×7=700 phút, tương đương ~11,7 giờ công/tuần.
-
Với đơn giá nhân sự phân tích 120.000 đ/giờ, giá trị thời gian tiết kiệm/tuần: 11,7×120,000≈1,404,000 đồng.
-
-
Quyết định kinh doanh rút ra từ dữ liệu:
-
Tăng phân bổ ngân sách và tồn kho vào khung 19:30–22:30, đặc biệt cho nhóm SKU_A1 và SKU_B7; thiết kế combo dành riêng cho khung 12–14h để đẩy AOV.
-
Giảm đốt ngân sách ở khung 00–02h, chuyển sang tập trung voucher/ưu đãi phí ship thay vì giảm giá trực tiếp, vì nhóm này mẫn cảm phí vận chuyển hơn giá.
-
Sắp xếp ca trực CS/OMS phù hợp với nhịp đơn theo khung giờ, giảm tắc nghẽn xác nhận đơn trong 30 phút đầu của khung 20–22h.
-
-
Cải thiện tuần kế tiếp (minh họa dự phóng dựa trên thử nghiệm A/B nhỏ trong 2 ngày):
-
GMV tăng thêm ~8,4% khi tái phân bổ ngân sách ads theo tỉ trọng net revenue khung giờ tuần trước.
-
Tỉ lệ hết hàng trong đỉnh (20–22h) giảm từ 11 SKU xuống 6 SKU khi đẩy thêm tồn kho cho top 20 SKU.
-
-
Trạng thái tối ưu kỹ thuật:
-
Chưa tối ưu các node: xử lý còn tuần tự theo file, chưa bật song song theo sàn/ngày, chưa cache bảng sku→product_name.
-
Kế hoạch tuần 2–3: bật xử lý song song theo file, thêm bộ nhớ tạm cho lookup tên sản phẩm, và chuyển raw log sang cơ sở dữ liệu khi số dòng vượt 1 triệu để tránh chậm khi append.
-
-
Công thức và chỉ số cốt lõi dùng trong tổng hợp:
-
Doanh thu gộp: GMV=∑(price×qty).
-
Doanh thu ròng: Net Revenue=∑[qty×(price−discount)].
-
Giá trị đơn trung bình: AOV=Net RevenueSoˆˊ đơn.
-
Tốc độ bán theo phút trong khung: Sales Rate=Units Sold khungPhuˊt trong khung.
-
Tổng kết thực thi tuần đầu cho thấy kiến trúc đơn giản “thả file vào thư mục – tự động tổng hợp – ghi sheet – di chuyển file đã xử lý” đủ đem lại giá trị rõ rệt: tiết kiệm thời gian tổng hợp, có ngay bức tranh khung giờ – SKU để ra quyết định nhanh, và tạo nền tảng chuẩn để tối ưu hiệu năng ở các tuần sau. Lưu ý quan trọng là duy trì bảng ánh xạ cột theo sàn/đợt, kiểm thử mẫu hằng ngày, và từng bước tách các khối ingest/transform/aggregate để quá trình tối ưu không ảnh hưởng nghiệp vụ.
Tải File cài đặt AI Automation
Liên hệ tư vấn chuyên sâu theo yêu cầu
- Dịch Vụ AI Whitelabel: Giải Pháp Tối Ưu Cho Doanh Nghiệp
- Bảo vệ: AI Bot viết bài chuẩn SEO
- AI Automation – tự động đăng ảnh + caption lên bài viết theo khoản thời gian chỉ định hằng ngày lên Fanpage của Facebook
- AI trong Doanh nghiệp Việt Nam: Ứng dụng Thực Tiễn và Lợi Ích Đột Phá
- [Tool Dùng Online] AI Automation – Tìm ứng viên trên Linkedin
Bài viết cùng chủ đề:
-

MINIMAX API Key & Hermes Agent
-
NVIDIA API Key & Hermes Agent
-

[Tool Dùng Online] AI Automation – Tender / Bidding Hunter: Giải Pháp “Săn” Gói Thầu & Soi Giá Đối Thủ B2B Tự Động
-

[Tool Dùng Online] AI Automation – “Vũ Khí” Săn Data Excel & Dữ Liệu Thô (Raw Data) Cho Doanh Nghiệp
-

[Tool Dùng Online] AI Automation – Công Cụ “Săn” Báo Cáo & Insight Thị Trường
-

[Tool Tải về] AI Automation – Ghi âm và tóm tắt cuộc họp
-

[Tool Tải Về] AI Automation – Chuyển văn bản thành giọng nói
-

[Tool Dùng Online] AI Automation – “Đọc Vị” Tâm Lý & Hành Vi Khách Hàng
-

[Tool Dùng Online] AI Automation – SEO & Research X-Ray Pro
-

[Tool Dùng Online] AI Automation – Logistics Lead Hunter
-

[Tool Dùng Online] AI Automation – Global Supplier Finder
-

[Tool Dùng Online] AI Automation – Global Import Partner Finder
-

[Tool Dùng Online] AI Automation – Tìm KOC/KOL cho sản phẩm
-

[Tool Dùng Online] AI Automation – Tìm Job trên Linkedin
-

[Tool Dùng Online] AI Automation – Tìm ứng viên trên Linkedin
-

AI Automation – chuyển youtube video dài thành nhiều video ngắn